Overview¶
The data access system deals primarily with the storage, retrieval and querying of
Datasets. An example of such a Dataset could be a
calibrated exposure (calexp) for a particular instrument corresponding to a
particular visit and sensor, produced by a particular processing run.
These Datasets form both the input and output of units of work called Quanta, and the data access system is also responsible for tracking the relations between them.
The in-memory manifestation of a Dataset (e.g. as a Python object) is called a InMemoryDataset. The Butler is the user-facing interface employed to load and store InMemoryDatasets.
Datasets are associated with a DatasetType, which combines a name (e.g. “calexp”) with a StorageClass (e.g. “Exposure”) and a set of DataUnit types (e.g. “visit” and “sensor”) that label it. The StorageClass defines both the Python type used for InMemoryDatasets and the (possibly multiple) storage formats that can be used to store the Datasets.
Relations between Datasets, Quanta, and locations for stored objects are kept in a database called a Registry which implements a common SQL schema.
In the database, the Datasets are grouped into Collections, Within a given Collection a Dataset is uniquely identified by a DatasetRef.
Conceptually a DatasetRef is a combination of a DatasetType and a set of DataUnits. A DataUnit holds the label (e.g. visit number) and metadata (e.g. observation date) associated with a discrete unit of data. DataUnits can also hold links to other DataUnits, such as the filter (itself a valid unit of data) associated with a visit.
A DatasetRef is thus a label that refers to different-but-related Datasets in different Collections.
For example, a DatasetRef might refer to the calexp for a particular visit and sensor; this could be used retrieve different Datasets produced by different processing runs.
A DatasetLabel is an opaque, lightweight DatasetRef that is easier to construct.
It just holds POD values that identify DataUnits and the name of a DatasetType, while the full DataUnit and DatasetType objects held by a DatasetRef contain information that in general must be retrieved from a Registry.
Storing the Datasets themselves, as opposed to information about them, is the responsibility of the Datastore.
An overview of the framework structure can be seen in the following figure:
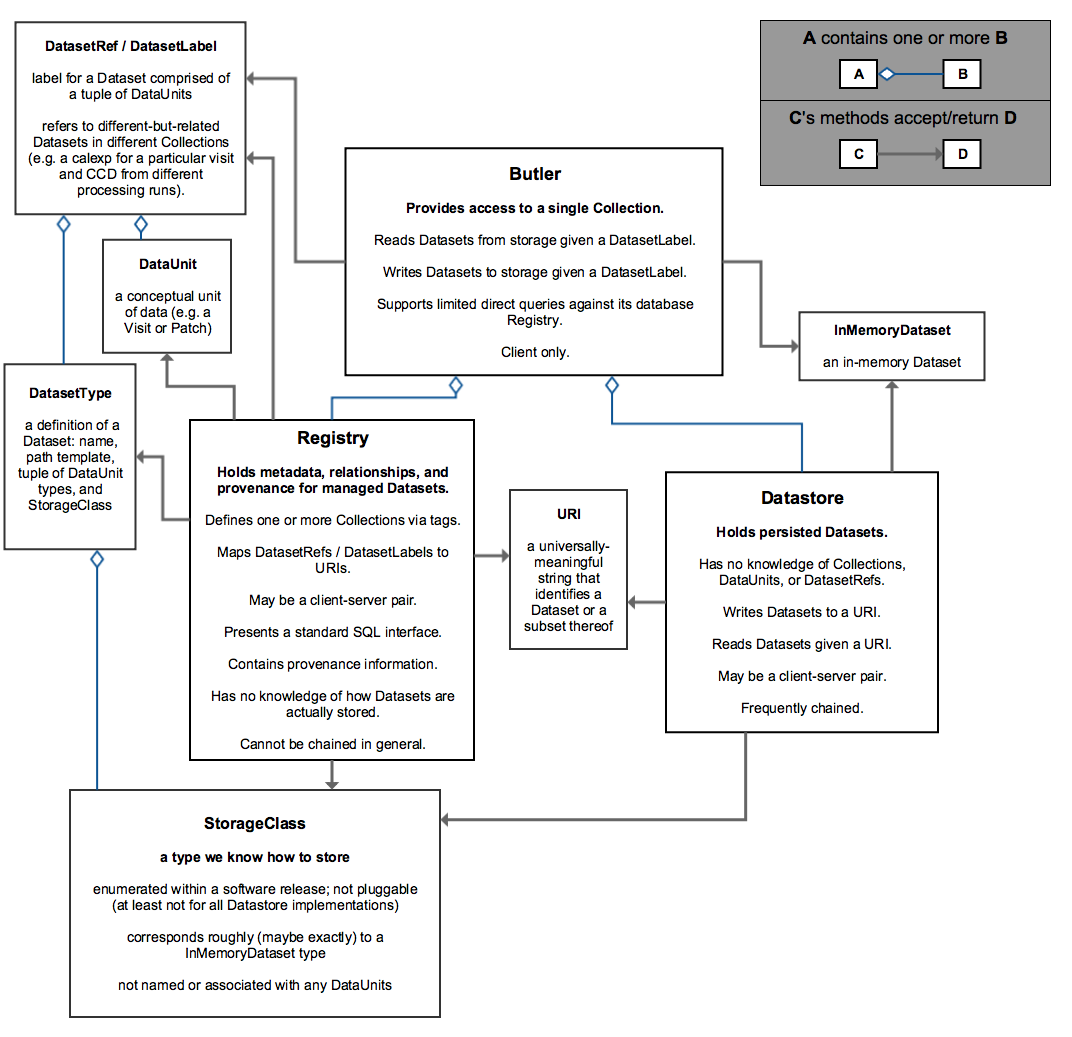
Users primarily interact with a particular Butler instance that provides access to a single Collection.
They can use this instance to:
- Load a Dataset associated with a particular
DatasetLabel, - Store a Dataset associated with a particular
DatasetLabel.
The Butler implements these requests by holding a single instance of Registry and a single instance of Datastore (as well as a Collection), to which it delegates the calls (note, however, that this Datastore may delegate to one or more other Datastores).
Currently, Registry must be used directly to perform general metadata and relationship queries, though we may add Butler forwarding interfaces for these as the design matures.
These components constitute a separation of concerns:
- Registry has no knowledge of how Datasets are actually stored, and
- Datastore has no knowledge of how Datasets are related and their scientific meaning (i.e. knows nothing about Collections, DataUnits and DatasetRefs).
This separation of concerns is a key feature of the design and allows for different implementations (or backends) to be easily swapped out, potentially even at runtime.
Communication between the components is mediated by the:
- URI that records where a Dataset is stored, and the
- StorageClass that holds information about how a Dataset can be stored.
The Registry is responsible for providing the StorageClass for stored Datasets and the Datastore is responsible for providing the URI from where it can be subsequently retrieved.
Note
Both the Registry and the Datastore typically each come as a client/server pair. In some cases the server part may be a direct backend, such as a SQL server or a filesystem, that does not require any custom software daemon (other than e.g. a third-party database or http server). In some cases, such as when server-side slicing of a Dataset is needed, a daemon for at least the Datastore will be required.